The Snorkel team is now focusing their efforts on Snorkel Flow, an end-to-end AI application development platform based on the core ideas behind Snorkel—check it out here!
The Snorkel project started at Stanford in 2016 with a simple technical bet: that it would increasingly be the training data, not the models, algorithms, or infrastructure, that decided whether a machine learning project succeeded or failed. Given this premise, we set out to explore the radical idea that you could bring mathematical and systems structure to the messy and often entirely manual process of training data creation and management, starting by empowering users to programmatically label, build, and manage training data.
To say that the Snorkel project succeeded and expanded beyond what we had ever expected would be an understatement. The basic goals of a research repo like Snorkel are to provide a minimum viable framework for testing and validating hypotheses. Four years later, we’ve been fortunate to do not just this, but to develop and deploy early versions of Snorkel in partnership with some of the world’s leading organizations like Google, Intel, Stanford Medicine, and many more; author over sixty peer-reviewed publications on our findings around Snorkel and related innovations in weak supervision modeling, data augmentation, multi-task learning, and more; be included in courses at top-tier universities; support production deployments in systems that you’ve likely used in the last few hours; and work with an amazing community of researchers and practitioners from industry, medicine, government, academia, and beyond.
However, we realized increasingly–from conversations with users in weekly office hours, workshops, online discussions, and industry partners–that the Snorkel project was just the very first step. The ideas behind Snorkel change not just how you label training data, but so much of the entire lifecycle and pipeline of building, deploying, and managing ML: how users inject their knowledge; how models are constructed, trained, inspected, versioned, and monitored; how entire pipelines are developed iteratively; and how the full set of stakeholders in any ML deployment, from subject matter experts to ML engineers, are incorporated into the process.
Over the last year, we have been building the platform to support this broader vision: Snorkel Flow, an end-to-end machine learning platform for developing and deploying AI applications. Snorkel Flow incorporates many of the concepts of the Snorkel project with a range of newer techniques around weak supervision modeling, data augmentation, multi-task learning, data slicing and structuring, monitoring and analysis, and more, all of which integrate in a way that is greater than the sum of its parts–and that we believe makes ML truly faster, more flexible, and more practical than ever before.
Moving forward, we will be focusing our efforts on Snorkel Flow. We are extremely grateful for all of you that have contributed to the Snorkel project, and are excited for you to check out our next chapter here.
Build
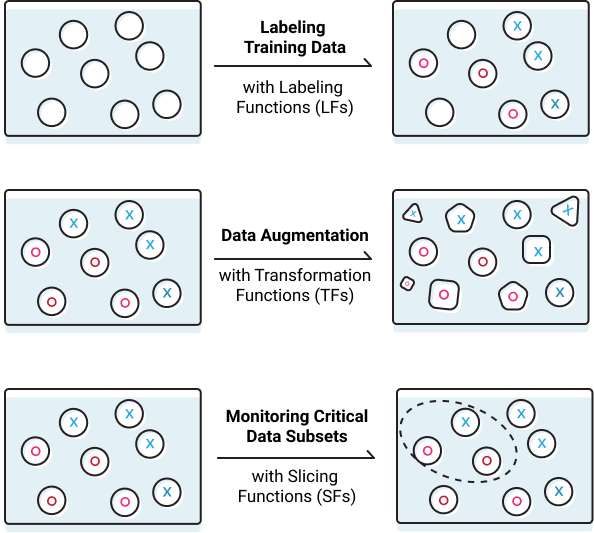
Labeling and managing training datasets by hand is one of the biggest bottlenecks in machine learning. In Snorkel, write heuristic functions to do this programmatically instead!
Get Started!Model
Programmatic or weak supervision sources can be noisy and correlated. Snorkel uses novel, theoretically-grounded unsupervised modeling techniques to automatically clean and integrate them.
Read More!Train
Snorkel outputs clean, confidence-weighted training datasets that easily plug into any modern machine learning framework.
Tutorialsstart in minutes
# For pip users
pip install snorkel
# For conda users
conda install snorkel -c conda-forge